4 Essential GitOps Principles You Need to Know
Anjelica Ambrosio


The soaring popularity of cloud-native applications and infrastructure has become a turning point for software development and deployment practices. More organizations and engineers are using Kubernetes in their products, causing a shift in the industry standard. However, with change also comes a set of challenges. Kubernetes can be complex and difficult for newcomers to navigate. Additionally, it often requires significant resources and financial investment due to the infrastructure and expertise necessary for effective maintenance and scaling.
With these challenges present, there is a demand for technologies and tools to lighten the burden. Given the complexity and challenges of managing cloud-native ecosystems with Kubernetes, there is a clear need for tools to simplify this process. There also exists a need for DevOps practices to change in order to enable developers to work more efficiently. Thus, the industry shifted towards a practice known as GitOps. This led to the creation of tools like Argo CD and Flux, which are built upon GitOps principles that have significantly eased the burden for developers and DevOps professionals.
What is GitOps?
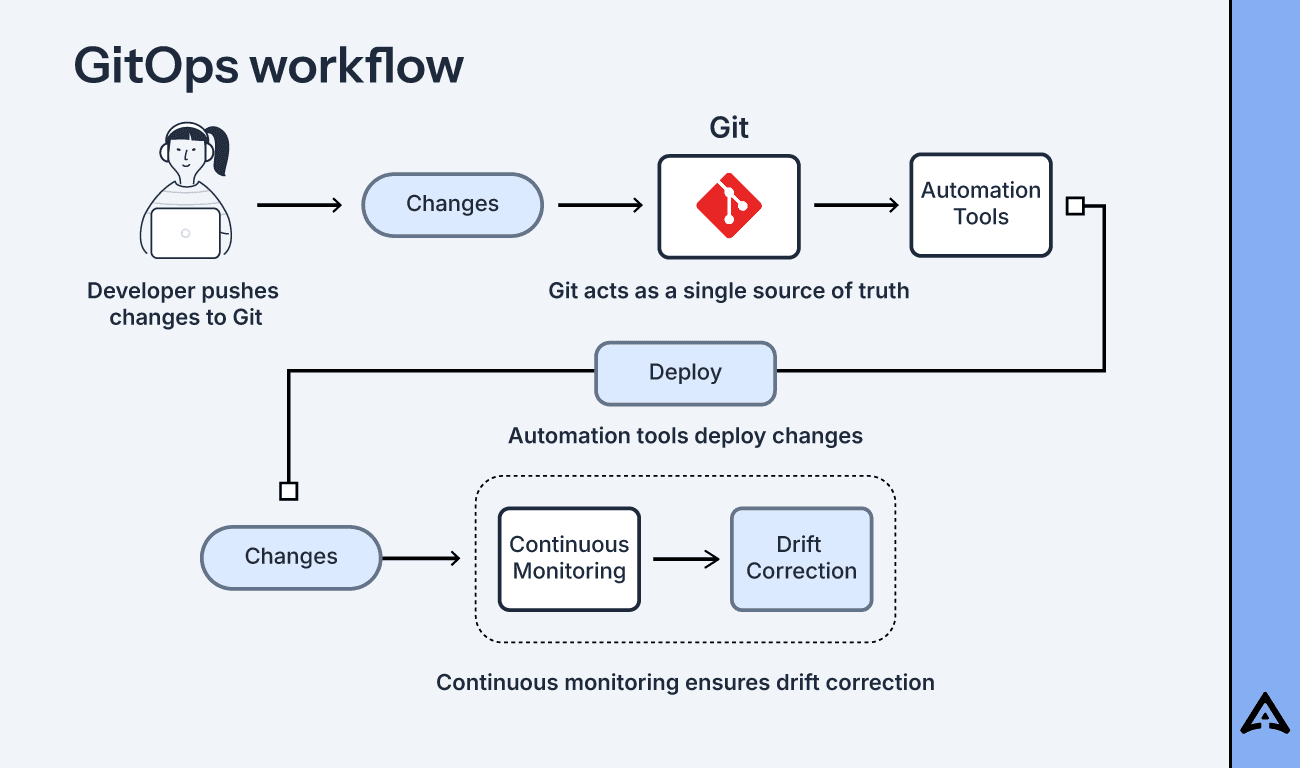
GitOps is a set of practices for managing infrastructure that can improve the efficiency of the development process. The term "GitOps" is a combination of the words "Git" and "Operations." GitOps uses a combination of CD (continuous delivery) pipelines, automated deployment processes, and IaC (Infrastructure as Code). To best describe GitOps in one sentence: GitOps is an approach that uses Git as the single source of truth for application and infrastructure configurations.
Git is a version control system that tracks different versions of files and is regarded as the world's most widely used version control system - an industry standard. Simply put, Git takes a snapshot of what your files look like at that moment and stores away a reference to the snapshot. Git also has a branching system that allows developers to make copies of the same code and work on it simultaneously. Git makes it easy to retrieve a copy of the code with pull requests, which pulls the code from the source, as the name suggests. We can also upload changes by pushing the code back to the source. We can use merge requests to merge branches and allow code changes to be reviewed and implemented.
Having a source of truth like Git at the center of delivery pipelines greatly benefits developers. The ability to make pull requests to help accelerate and simplify application deployments and operations to Kubernetes lightens the burden significantly.
Key Benefits of GitOps:
Version-controlled infrastructure with Git
Automated deployments using CI/CD pipelines
Faster rollback & disaster recovery with immutable versioning
Enhanced security & compliance with declarative configurations
The Four Key Principles of GitOps
The OpenGitOps project has established four fundamental principles that define GitOps, which we will use as our reference point in this article.

Principle #1: Declarative
The first fundamental principle of GitOps: "A system managed by GitOps must have its desired state expressed declaratively." With GitOps, the desired state, or Git, is the one source of truth. The desired state is the ideal state of the project you envision it to be. You must have a clear blueprint for what this system looks like to achieve your desired state. This is our image of what we want the result to look like. This blueprint is typically saved in a Git repository, and the system will look to only what is here as our single source of truth. So, to follow the first GitOps fundamental, the system will look only to the file saved in Git as it is our single source of truth. Compare this to imperative computing, in which the user defines the desired state and takes the necessary actions and steps to achieve it, whereas GitOps uses a declarative approach which allows the user to define the declarative state and enable the system to take the necessary actions and steps to achieve it.
For example, with Kubernetes, we use a YAML file (fun fact: YAML stands for Yet Another Markup Language) to give concise orders of what this desired state is and its rules. We use this to recreate an application or system and ensure that this recreation is faithful to its desired state. In this case, the YAML file is the only source of truth. The computer goes down each line in the file and applies these directives and sets of rules to the system state, or the current system configuration. Keep in mind: if something in the system state contradicts the desired state, it will automatically try to remedy this contradiction so the system state will always match the desired state.
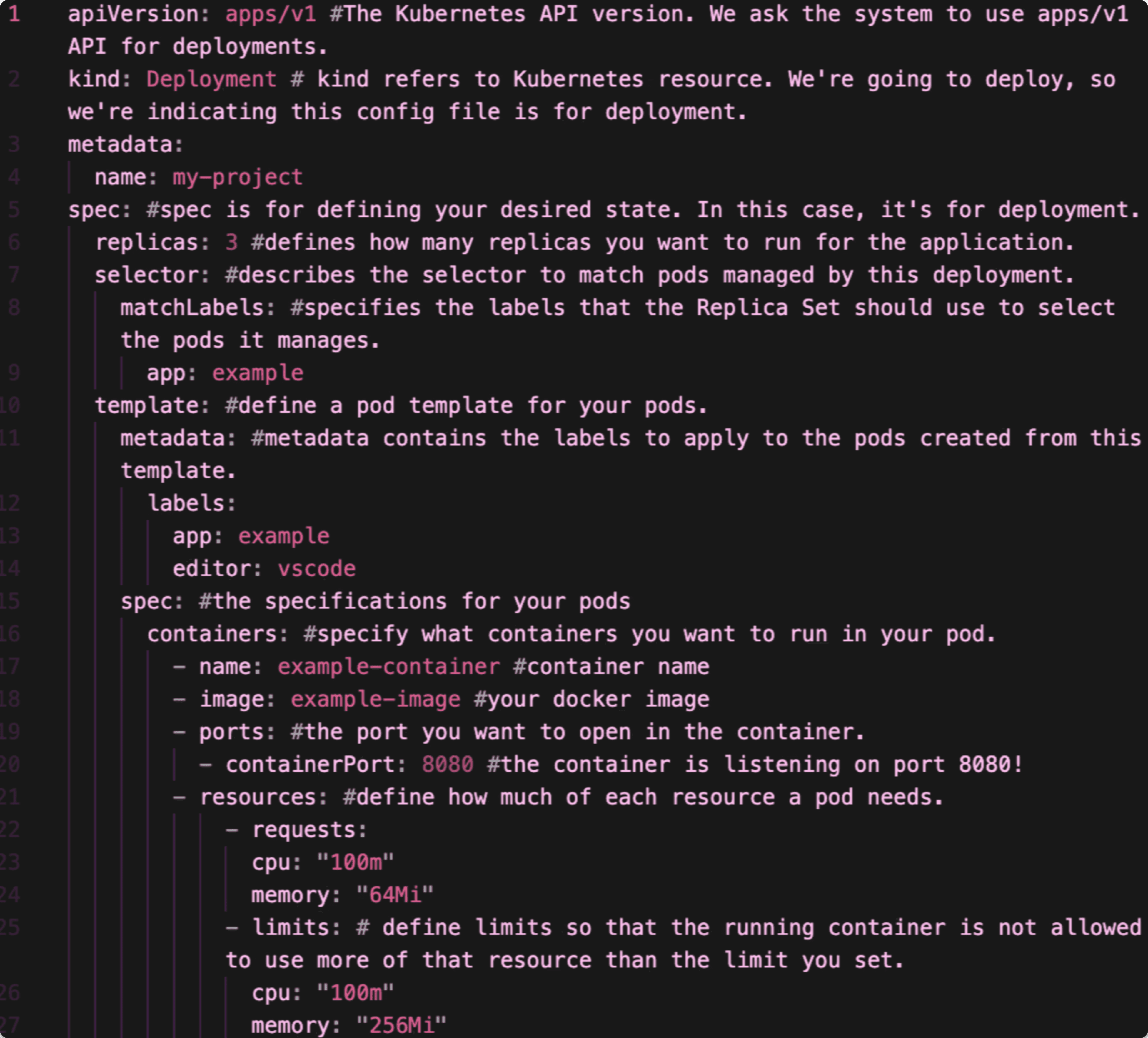
YAML File Example
Please take a look at the example YAML file above. The system will read this file line by line. See the comments in the image for notes on what these fields detail to the system. These are our declarations to the system on what we are trying to achieve, our desired state. From this file alone, we can tell: what API version we intend to use, what Kubernetes resource we intend to use, how many replicas we want to run, what containers run in the pod, etc. The system will go ahead and deploy with these specifications in mind.
Principle #2: Versioned and Immutable
The second fundamental principle of GitOps: "Desired state is stored in a way that enforces immutability, versioning and retains a complete version history." Recall that Git takes a snapshot of what your files look like at that moment and stores away a reference to that snapshot. The snapshot is immutable, meaning that it cannot be changed. If changes were made, then it would be as a new version of the snapshot. The original that is stored away wouldn't be changed, and the revision would be regarded as the next version.
Developers can observe version history logs to see changes in each version or pull an older code version. This is called a rollback. Sometimes, we need to use older versions of software or config files due to reasons such as compatibility issues. Or, if there's an issue with the newest version, we can easily rollback to the last stable build. So it's convenient to have immutable versions of a product to return to if needed.
Principle #3: Pulled Automatically
The third fundamental principle of GitOps: "Software Agents automatically pull the desired state declarations directly from the source." GitOps works without the need for webhooks or any other event-driven way for one application to send information to another. This is why the manifest is pulled automatically, instead of relying on an event. Remember, your desired state was declared in a file and typically saved in Git. That file in Git is our one source of truth. That file contains the instructions and set of rules we declared, to create our desired state. If you have several Kubernetes clusters, you'll have several YAML files. Now, nobody wants to actually manually go and apply these manifests to EACH cluster. Time is money, right? This is where software agents come into play. Software agents are programs that carry out a task continuously for a user or an organization, such as a Kubernetes controller. For example, Argo CD is implemented as a Kubernetes controller. These Kubernetes controllers work like a reconciliation agent and regulate the state of the system. They automatically pull manifests (e.g. YAML) from your source (e.g. Git repository) and apply them to your cluster, so you don't have to.
Principle #4: Continuously Reconciled
The fourth fundamental principle of GitOps: "Software Agents continuously observe system state and attempt to apply the desired state." As mentioned above, Software Agents are like reconciliation agents that observe and regulate the system state. These Software Agents look to Git as their one source of truth; it is their job to attempt to reconcile or fix the system state to match the desired state.
What Are the Benefits of Using GitOps?
Working with Kubernetes can be VERY time-consuming. So why not make it easier on yourself? GitOps makes creating infrastructure easier, faster, and scalable. Kubernetes is declarative, where the user defines the desired state via the YAML file, allowing the system to carry out building the desired state, which is much more efficient than imperative computing. Some organizations have thousands of development environments (containers), and it would be highly impractical to manage them all manually. It’s no wonder why so many organizations are adopting GitOps practices.
Take GitOps to the Next Level with Expert Insights
GitOps is transforming the way teams manage Kubernetes, offering a streamlined, automated approach to infrastructure and application deployment. By leveraging Git as a single source of truth and adopting best practices, organizations can improve efficiency, security, and scalability.
But implementing GitOps effectively requires the right strategies and tools. To dive deeper into GitOps best practices, Kubernetes YAML management, CI/CD workflows, and more, watch our expert-led webinar:
Looking for more resources? Check out our free course on GitOps and Continuous Delivery or schedule a technical demo to see GitOps in action. Have questions? Join the conversation in our community discord!
Frequently Asked Questions About GitOps Principles
What are the key principles of gitops?
The key principles of GitOps are declarative configuration, version-controlled state, automated reconciliation, and continuous delivery through Git as the single source of truth. All infrastructure and application configurations must be defined declaratively and stored in Git repositories. A GitOps controller (like Argo CD) continually compares the desired state in Git to the live state in the cluster and automatically syncs or alerts on any drift. This ensures consistency, repeatability, and secure, auditable change management.
What are the 7C's of DevOps?
The 7 C’s of DevOps typically refer to Culture, Collaboration, Continuous Integration, Continuous Testing, Continuous Delivery/Deployment, Continuous Monitoring, and Continuous Feedback. These principles describe the practices and mindset needed to streamline software delivery from development through operations. Together, they support faster release cycles, higher reliability, and a culture of shared responsibility across teams.
What are the basics of gitops?
The basics of GitOps revolve around using Git as the single source of truth for all infrastructure and application configuration. You define your desired state declaratively in Git, and a GitOps tool like Argo CD automatically applies and continuously reconciles that state to your Kubernetes cluster. Any change, whether deploying new code or updating infrastructure, is made through a Git commit, giving you built-in versioning, auditability, and rollback capabilities. This approach ensures consistency, reliability, and automated drift detection across environments.
What is a YAML file?
A YAML file is a human-readable data serialization format used to define configuration in a structured but easy-to-read way. YAML (short for “YAML Ain’t Markup Language”) uses indentation rather than brackets, making it cleaner and more intuitive than JSON or XML. In Kubernetes, GitOps, CI/CD, and many DevOps tools, YAML files are used to declare the desired state of resources, such as deployments, services, workflows, or policies, so systems can automatically apply and manage them.
